Checking In
It’s been a few days since my first entry in this series. For the most part, things have been going quite smoothly. I have to say, I am liking KDE Plasma Workspaces 6 much better than previous releases (which I dabbled with but admittedly did not spend a significant amount of time using). The majority of what I want to do here Just Works. This should probably not come as a surprise to me, but I’ve been burned before when jumping desktops.
I suppose that should really be my first distinct note here: the transition from GNOME Desktop to KDE Plasma Workspaces has been minimally painful. No matter what, there will always be some degree of muscle memory that needs to be relearned when changing working environments. It’s as true going from GNOME to KDE as it is from Windows to Mac, Mac to ChromeOS and any other major shift. That said, the Fedora Change that prompted this investigation is specifically about the possibility of changing the desktop environment of Fedora Workstation over to using KDE Plasma Workspaces and away from GNOME. As such, I will be keeping in mind some of the larger differences that users would face in such a transition.
Getting fully hooked up
The first few days of this experience, I spent all of my time directly at my laptop, rather than at my usual monitor-and-keyboard setup. This was because I didn’t want to taint my initial experience with potential hardware-specific headaches. My main setup involves a very large 21:9 aspect monitor, an HDMI surround sound receiver and a USB stereo/mic headset connected via a temperamental USB 3.2/Thunderbolt hub and the cheapest USB A/B switch imaginable (I share these peripherals with an overpowered gaming PC). So when I put aside my usual daily driver and plugged my Thinkpad into the USB-C hub, I was prepared for the worst. At the best of times, Fedora has been… touchy about working with these devices.
Let’s start with the good bits: When I first connected the laptop to my docking station, I was immediately greeted by an on-screen display asking me how I wanted to handle the new monitor. Rather than just making a guess between cloning or spanning the desktop, it gave me an easy and visual prompt to do so. Unfortunately, I don’t have a screenshot of this, as after the first time it seems that the system “remembers” the devices and puts them back the way I had them. This is absolutely desirable for the user, but as a reviewer it makes it harder to show it off. (EDIT: After initial publication, I was informed of the meta-P shortcut which allowed me to grab this screenshot)
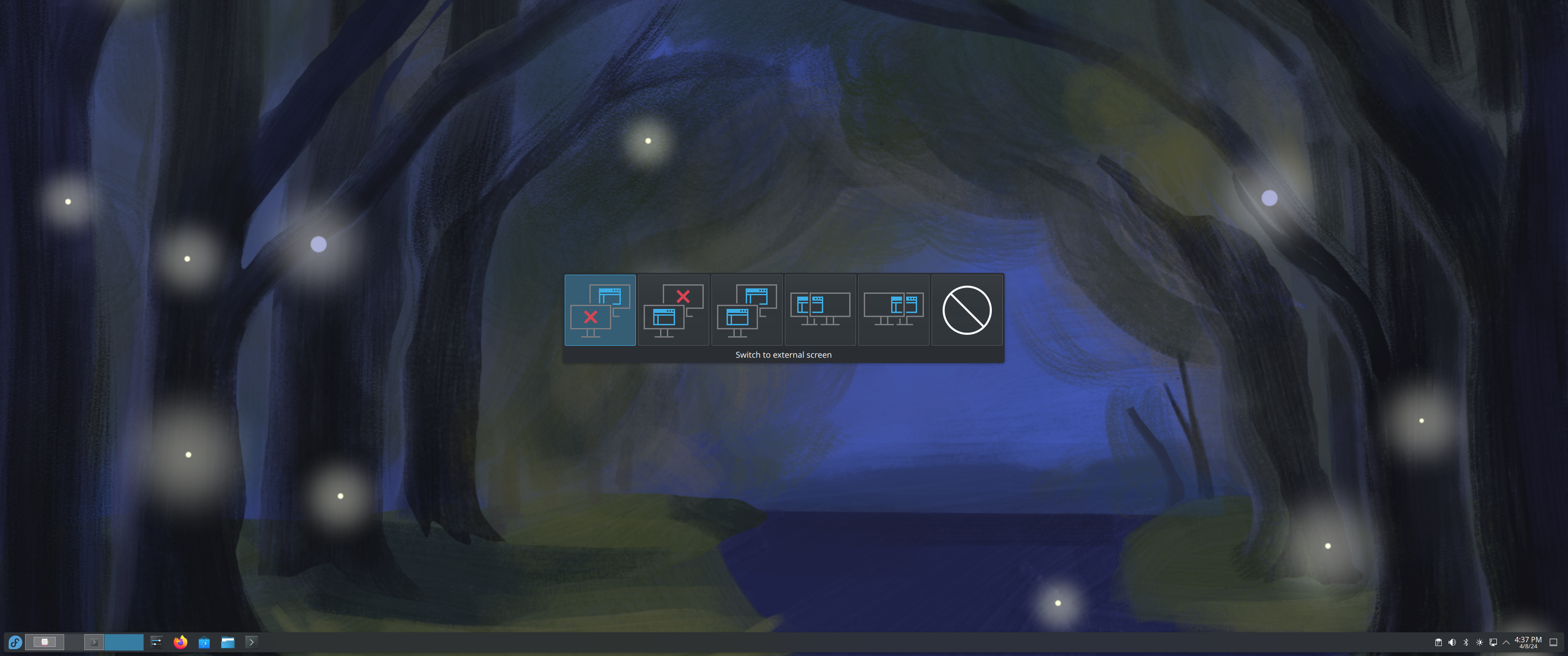
Something else that I liked about the multi-monitor support was the way that the virtual desktop space on the taskbar automatically expanded to include the contents from both screens. It’s a simple thing, but I found that it made it really easy to tell at a glance which desktop I had particular applications running on.
All in all, I want to be clear here: the majority of my experience with KDE Plasma Workspaces has been absolutely fine. So many things work the same (or close enough) to how they work in GNOME that the transition has actually been much easier than I expected. the biggest workflow changes I’ve encountered are related to keyboard shortcuts, but I’m not going to belabor that, having discussed it in the first entry. The one additional keyboard-shortcut complaint I will make is this: using the “meta” key and typing an application name has a strange behavior that gets in my way. It almost behaves identically to GNOME; I tap “meta” and start typing and then hit enter to proceed. But the issue I have with KDE is this: I’m a fast typist and the KDE prompt doesn’t accept <enter> until the visual effect of opening the menu completes. This baffles me, as it accepts all of the other keys. So my muscle memory to launch a terminal by quickly tapping “meta”, typing “term” and hitting enter doesn’t actually launch the terminal. It leaves me at the menu with konsole sitting there. When I hit enter after the animation completes, it works fine. So while the behavior isn’t wrong, per se, it’s frustrating. The fact that it accepts the other characters makes me think this was a deliberate choice that I don’t understand.
There have been a few other issues, mostly around hardware support. I want to be clear: I’m fully aware that hardware is hard. One issue in particular that has gotten in the way is support for USB and HDMI sound devices in KDE Plasma. I don’t know if it’s specifically my esoteric hardware or a more general problem, but it has been very hard to get KDE to use the correct inputs and outputs. In the case of the HDMI audio receiver, I still haven’t been able to get KDE to present it as an output option in the control panel. It connects to the receiver and treats it as a very basic 720p video output device, but it just won’t recognize it as an audio output device. My USB stereo headset with mic has also been more headache than headset: after much trial and error, I’ve managed to identify the right output to send stereo output to it, but no matter what I have fiddled with, it does not recognize the microphone.
More issues on the hardware front are related to having two webcam devices available. KDE properly detects both the built-in camera on the laptop as well as the external webcam I have clipped to the top of my main monitor, but it seems to have difficulty switching between them. I’m not yet 100% sure how much of this is a KDE problem and how much a Firefox problem, but it is frustrating. Sometimes I’ll select my external webcam and it will still be taking input from the built-in camera. Also, it seems to always show two entries for both devices. I need to do more digging here, but I anticipate that I’ll be filing a bug report once I gather enough data.
Odds and Ends
I have mixed feelings about KDE’s clipboard applet in the toolbar. On the one hand, I can certainly see the convenience of digging into the clipboard history, particularly if you accidentally drag-select something and replace the clipboard copy you intended to keep. On the other hand, as a heavy user of Bitwarden who regularly copies passwords1 out of the wallet and into other applications, the fact that all of the clipboard contents are easily viewable in plaintext to anyone walking by if I forget to lock my screen for a few seconds is quite alarming. I’m pretty sure I’ll either have to disable this applet or build a habit of clearing it any time I copy a password. Probably the former, as I don’t like the fact that I have to call up and make the plaintext visible first in order to delete it without clearing the entire history anyway.
Conclusion
This will probably seem odd after a post that mostly contained complaints and nitpicks, but I want to reiterate: my experience over the last several days has actually been quite good. When dealing with a computer, I consider “it was boring” to be the highest of praise. Using KDE has not been a life-altering experience. It has been a stable, comfortable environment in which to get work done. Have I experienced some issues? Absolutely. None of them are deal-breakers, though the audio issues are fairly annoying. My time in the Fedora Project has shown me that hardware issues inevitably get fixed once they are noticed, so I’m not overly worried.
As for me? I’m going to stick around in KDE for a while and see how things play out. If you’re reading this and you’re curious, I’ll happily direct you to the Fedora KDE Spin for the Live ISO or the Kinoite installer if, like me, you enjoy an atomic update environment. Make sure to select “Show Beta downloads” to get Plasma 6!
- I generate high-entropy, unique random passwords for everything. Don’t you? ↩︎